Einleitung
MonArch bietet eine umfangreiche Funktion zum Importieren strukturierter Daten aus Excel- und CSV-Dateien. Diese Importfunktion (insbesondere auch in Kombination mit der ähnlich aufgebauten Export-Funktion) ist ein zentrales Werkzeug zur effizienten Datenübernahme und -aktualisierung innerhalb des Systems. Mit ihrer Hilfe können verschiedenste Datentypen automatisiert in MonArch erstellt oder ergänzt werden. Derzeit ist ein Import folgender Typen möglich:
- Strukturelemente
- Interne Themen
- Externe Themen
- Personen
- Projektphasen
- Strukturtypen
- Digitale Dokumente
- Analoge Dokumente
- Notizen
- Weblinks
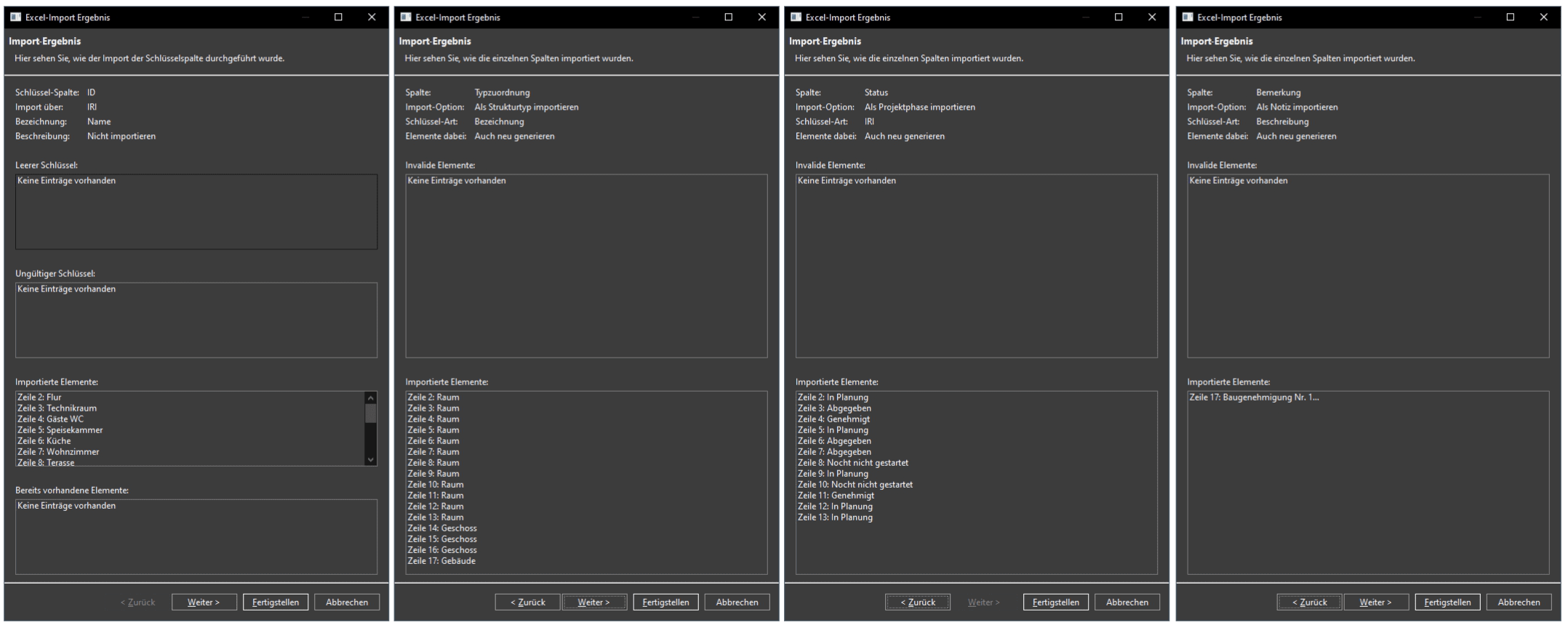
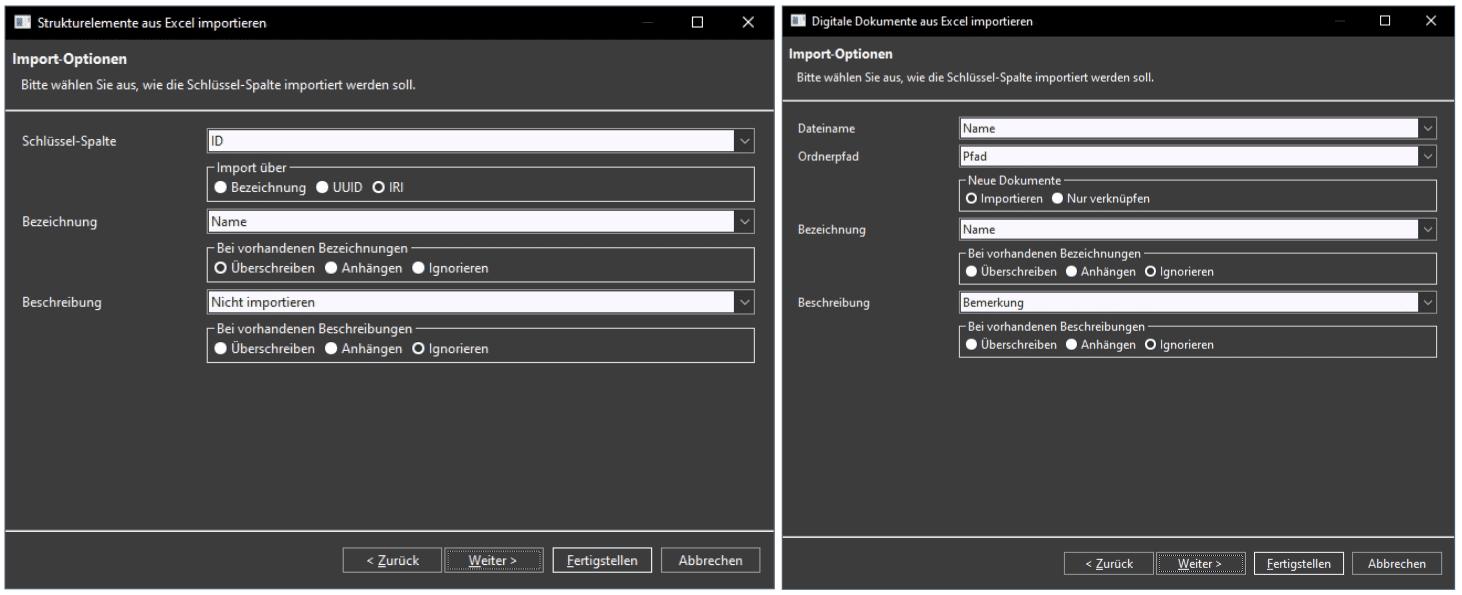
Die Importfunktion ist in den verschiedenen Ansichten von MonArch jeweils über das Menü unter dem Plus-Symbol in der Toolbar erreichbar – etwa in der Strukturhierarchie für Strukturelemente oder in der Ergebnisansicht für Dokumente. Nach dem Start des Imports öffnet sich ein mehrstufiger Dialog, der den Importprozess strukturiert anleitet und alle notwendigen Einstellungen Schritt für Schritt abfragt. Die Elemente der folgenden Tabelle wurden so zum Beispiel als Strukturelemente – einschließlich zugeordneter Eigenschaften, Typen, Notizen, Weblinks sowie mehrerer Personen und Projektphasen – importiert (s. Bild 1).
Seite 1: Auswahl der Datei
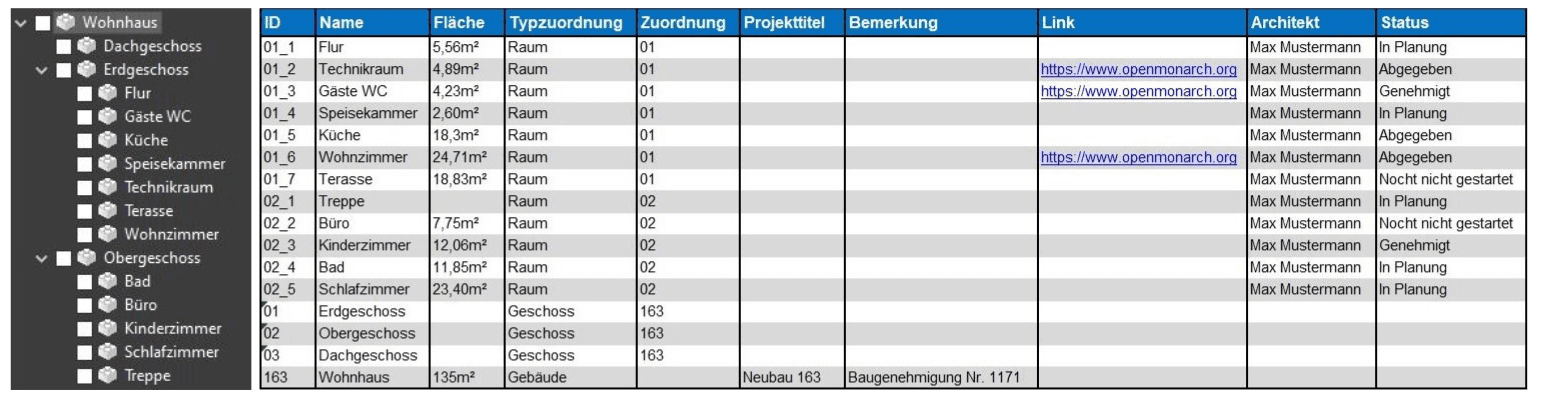
Der erste Schritt im Importprozess besteht aus der Auswahl der zu importierenden Datei. Hierbei kann entweder eine klassische Excel-Datei im .xlsx- bzw. .xls-Format oder alternativ eine CSV-Datei selektiert werden. Falls eine CSV-Datei verwendet wird, muss zusätzlich ein Spaltentrennzeichen angegeben werden – standardmäßig ist dies das Komma, es kann jedoch auch individuell angepasst werden (z. B. auf Semikolon oder Leerzeichen).
Neben der Datei selbst können auf dieser ersten Seite des Dialogs auch optionale Einstellungen vorgenommen werden. So besteht zum einen die Möglichkeit, eine zuvor gespeicherte Importkonfiguration zu laden. In diesem Fall werden sämtliche Einstellungen der folgenden Dialogseiten automatisch mit den gespeicherten Werten befüllt, was vor allem bei regelmäßig wiederkehrenden Importen Zeit spart und Konsistenz gewährleistet. Umgekehrt kann auch festgelegt werden, dass die beim aktuellen Import verwendeten Einstellungen am Ende als neue Konfigurationsdatei gespeichert werden sollen – beispielsweise für spätere Reimporte oder zur Weitergabe an Kollegen.
Ebenfalls optional ist die Generierung eines Importberichts. Dieser wird im PDF-Format gespeichert und enthält detaillierte Informationen über den Verlauf und das Ergebnis des Imports. Dazu zählen unter anderem die Anzahl importierter Zeilen und erzeugter Elemente und Verknüpfungen, erkannte Duplikate, Fehler oder fehlende Werte sowie Hinweise auf ungültige Daten.
Die einzige verpflichtende Angabe auf dieser Dialogseite ist der Pfad zur Datei, die importiert werden soll (s. Bild 2 links). Alle weiteren Optionen dienen der Flexibilität und Wiederverwendbarkeit des Prozesses.
Seite 2: Auswahl des Tabellenblatts und Zeilenbereichs
Nachdem die Datei ausgewählt wurde, liest MonArch im nächsten Schritt alle darin enthaltenen Tabellenblätter aus. Diese werden auf der zweiten Dialogseite in einem Dropdown-Menü angezeigt, aus dem das zu importierende Tabellenblatt ausgewählt werden muss (im Fall einer CSV-Datei steht hier nur der Wert „CSV“ zur Auswahl). Wird die selektierte Datei geändert, werden die vorhandenen Werte abermals ausgelesen. So können immer nur tatsächlich vorhandene Tabellenblätter ausgewählt werden.
Anschließend wird definiert, ab welcher Zeile der Import beginnen und bis zu welcher Zeile er durchgeführt werden soll. Auch die Zeile, in der sich die Spaltenüberschriften befinden, muss angegeben werden (s. Bild 2 rechts). Diese Überschriften dienen in den folgenden Schritten für Anwender als Referenz für die Zuordnung der verschiedenen Spalteninhalte. Es ist kein Problem, mehr Zeilen anzugeben als tatsächlich mit Inhalten gefüllt sind (z.B. bei Nutzung einer gespeicherten Importkonfiguration) – leere Zeilen werden automatisch ignoriert. Wichtig ist jedoch, dass die Zeilennummer der Überschrift über der ersten zu importierenden Zeile liegt und dass die gewählten Bereiche logisch zueinander passen (der Startwert also unter dem Endwert liegt). Eine interne Validierung stellt sicher, dass solche offensichtlichen Eingabefehler erkannt und entsprechend gemeldet werden. Ohne diese vollständigen Angaben zu Tabellenblatt und Zeilenbereich ist ein Fortfahren zum nächsten Schritt nicht möglich.
Seite 3: Schlüsselspalte und Basiseigenschaften
Die dritte Dialogseite widmet sich der Definition der Schlüsselspalte – also derjenigen Spalte, deren Inhalte eindeutige Kennungen enthalten, über die neue Elemente erzeugt oder bestehende wiedererkannt werden können. Diese Spalte ist zentral für die Identifikation und Strukturierung der zu importierenden Daten.
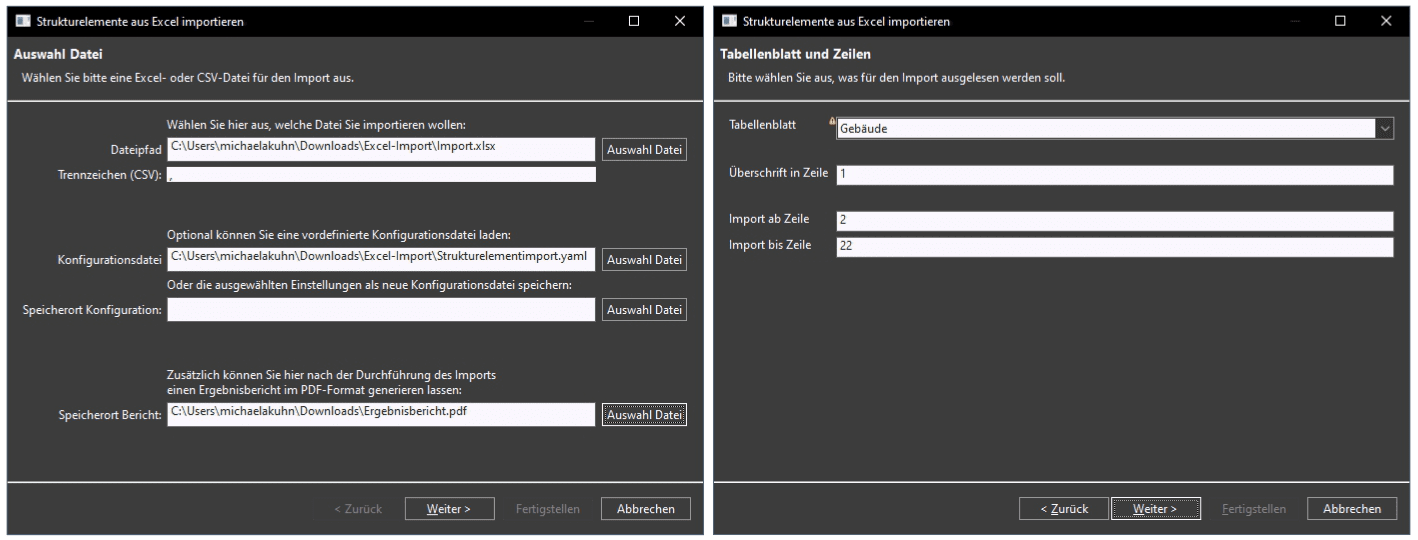
MonArch erlaubt hierbei verschiedene Methoden zur Auswertung der Schlüsselspalte (s.Bild 3 links). Wird sie als Bezeichnung genutzt, erfolgt die Identifikation des Elements anhand des Namens. Gibt es bereits ein Element mit diesem Namen, wird dieses verwendet; andernfalls wird ein neues erzeugt. Alternativ kann die Spalte als UUID oder IRI (URL) interpretiert werden, wodurch sich technische, eindeutige Kennungen für eine präzisere Wiedererkennung und Nachverfolgbarkeit nutzen lassen. So ist es zum Beispiel möglich, bei wiederholten Importen gezielt dieselben Objekte zu aktualisieren, statt neue zu erzeugen. In Fällen, in denen der zu importierende Datentyp (z.B. Strukturelemente oder interne Themen) in MonArch mit Abkürzungen arbeitet, kann auch diese Importvariante gewählt werden – vorausgesetzt, ein entsprechendes Abkürzungsfeld ist im Datenstand vorhanden. Zusammengefasst gibt es also folgende Möglichkeiten, die Schlüsselspalte in MonArch zu integrieren:
- Bezeichnung: Existiert bereits ein Element mit dieser Bezeichnung in MonArch, wird es wiederverwendet, ansonsten neu angelegt. Eine Umbenennung innerhalb MonArchs verhindert ein erneutes Wiederauffinden.
- UUID: Eindeutiger technischer Identifier in festem Format (bestehend aus 36 Zeichen). Ermöglicht immer eine spätere Wiedererkennung.
- IRI: Textbasierter Identifier. Ermöglicht eine spätere Wiedererkennung auch nach einer Umbenennung in MonArch. Diese Variante ist in den meisten Fällen empfohlen (da IRIs auch aus Namen generiert werden können).
- Abkürzung: Nur verfügbar, wenn der importierte Datentyp ein Abkürzungsfeld besitzt. Durchsucht vorhandene Elemente in MonArch anhand dieses Werts.
Hierbei gibt es einen Sonderfall: Der Import von Dokumenten unterscheidet sich grundlegend von anderen Elementtypen, da nicht bloß Metadaten, sondern tatsächliche Dateien verarbeitet werden. Die Schlüsselspalte muss in diesem Fall entsprechend entweder den vollständigen Pfad zu einer Datei enthalten oder alternativ zwei Spalten bereitstellen – eine mit dem Dateinamen und eine mit dem Ordnerpfad (s. Bild 3 rechts). Beim Import prüft MonArch für jede Zeile, ob die angegebene Datei vorhanden und lesbar ist. Anschließend wird sie in MonArch importiert – je nach ausgewählter Konfiguration entweder als Kopie auf den MonArch-Server oder nur als verknüpfte Referenz zu ihrem originalen Speicherort.
Ergänzend zu Schlüsselspalte bzw. Dateipfad kann auf der dritten Dialogseite auch angegeben werden, welche Spalte die Bezeichnung und welche die Beschreibung der neu erzeugten Elemente enthalten soll. Ersteres kann dabei nur separat gesetzt werden, wenn die Schlüsselspalte nicht bereits als Bezeichnung importiert wird. Für beide Felder lässt sich zudem definieren, wie beim Import mit in MonArch vorhandenen Werten verfahren werden soll: So können die neu aus der Tabelle ausgelesenen Werte entweder vollständig ignoriert, an bestehende Inhalte angehängt werden oder bestehende Inhalte komplett überschreiben. Folgende Importstrategien sind also für in MonsArch vorhandene Bezeichnungen bzw. Beschreibungen vorhanden:
- Überschreiben: Bestehende Werte werden komplett ersetzt.
- Anhängen: Neue Werte werden an bereits bestehende angefügt.
- Ignorieren: Bestehende Werte bleiben erhalten (Standard).
Die Auswahl der Spalten erfolgt auch hier wieder über Dropdown-Menüs, deren Einträge automatisch aus den Überschriftenzeilen des gewählten Tabellenblatts entnommen werden. Nicht benötigte Felder können zudem explizit auf „Nicht importieren“ gesetzt werden.
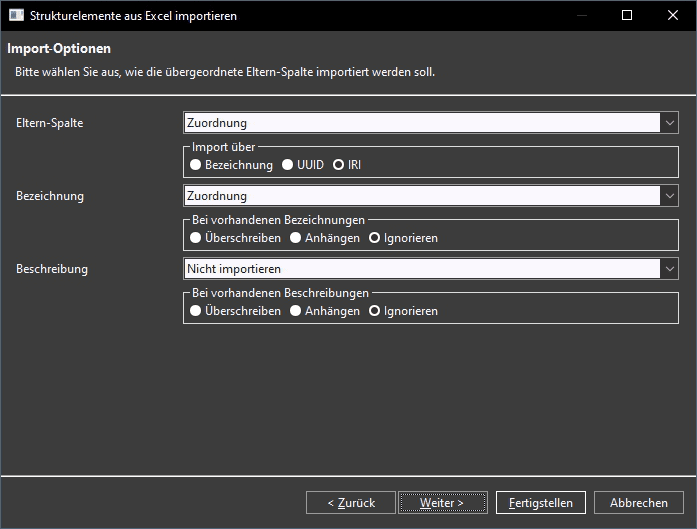
Seite 4: Hierarchische Zuordnungen (nur für Strukturelemente und Themen)
Für alle Elemente, die in MonArch in einer hierarchischen Struktur aufgebaut sind, also für Strukturelemente und alle Arten von Themen, wird auf einer weiteren Dialogseite festgelegt, ob bzw. wie die Beziehung zu übergeordneten Elementen aufgebaut werden soll (s. Bild 4). Für andere Importtypen, wie Dokumente oder Notizen, entfällt diese Seite vollständig.
Auch hier wird über eine eigene Spalte ein Schlüsselwert selektiert, der das Elternelement identifiziert. Wie bei der Schlüsselspalte des zu importierenden Elements kann auch hier über Bezeichnung, UUID, IRI oder – sofern möglich – über eine Abkürzung gearbeitet werden. Zusätzlich können auch hier Bezeichnung und Beschreibung des Elternelements separat mit importiert werden. Ein besonderer Komfort ist dabei, dass Spalten, die bereits im vorherigen Schritt für eine Importoption ausgewählt wurden, automatisch aus der Auswahl für Elternelemente entfernt werden. Dadurch wird verhindert, dass dieselbe Spalte für unterschiedliche Funktionen verwendet wird – eine wichtige Maßnahme zur Wahrung der Importlogik.
In der Beispieltabelle aus Bild 1 existiert die Spalte namens „ID“ mit Werten „01“, „01_1“, „01_2“ etc. sowie eine zweite Spalte namens „Zuordnung“, die jeweils auf die ID des übergeordneten Elements verweist. MonArch kann daraus im Import automatisch die ebenfalls im Bild dargestellte Strukturhierarchie erzeugen, die das Wohnhaus über Geschosse in einzelne Räume unterteilt. Die Elternelemente benötigen dabei keine eigene Spalte für das Setzen einer Bezeichnung, da diese bereits im ersten Importschritt bei der Generierung der Schlüsselelemente selbst gefüllt wird.
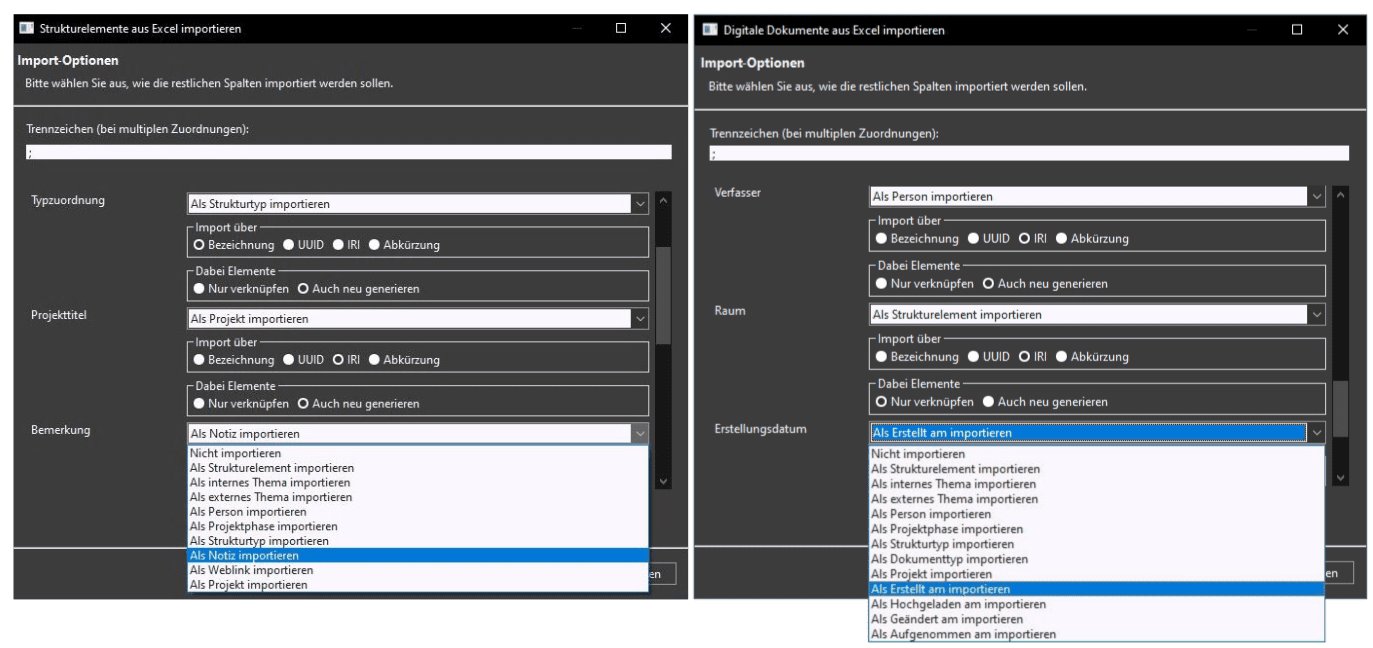
Seite 5: Verbleibende Spalten und Detailzuweisungen
Im letzten Schritt des Importdialogs werden alle übrigen Spalten aufgelistet, die bislang nicht für Schlüssel- oder Hierarchieangaben genutzt wurden. Für jede dieser Spalten kann nun individuell definiert werden, ob bzw. wie ihre Inhalte importiert werden sollen (s. Bild 5). Die Möglichkeiten reichen dabei von der Erstellung neuer Strukturelemente über die Zuweisung interner oder externer Themen, Personen, Projektphasen und Strukturtypen bis hin zur Übergabe der Spalteninhalte an bestimmte Eigenschaften des importierten Elements. Besonders bei Dokumenten können so beispielsweise weiterführende Informationen wie Erstell- oder Änderungsdaten oder Autoren direkt mit importiert werden. Auch Projekte können über diese Felder zugewiesen werden.
Für Strukturelemente und Themen stehen darüber hinaus spezielle Optionen zur Verfügung: Einzelne Spalten können als Notiz interpretiert werden – deren Inhalt wird dann als Beschreibung einer neuen Notiz verwendet – oder als Weblink, sofern die enthaltenen Werte gültige URLs darstellen. Im letzteren Fall ist zu beachten, dass nur korrekt formatierte URLs verarbeitet werden. Fehlerhafte Einträge werden im Importbericht aufgeführt, führen aber nicht zum Abbruch des Imports.
Wie bei den Schlüsselfeldern kann für jede Spalte auch hier festgelegt werden, über welchen Identifikationstyp (Bezeichnung, UUID, IRI oder ggf. Abkürzung) die Zuweisung erfolgen soll. Zusätzlich lässt sich bestimmen, ob für nicht im Datenstand vorhandene Elemente neue Einträge erzeugt werden sollen, oder ob nur eine Verknüpfung mit bereits existierenden Objekten erfolgen darf. Im Folgenden sind noch einmal alle Möglichkeiten des Imports einer Spalte sowie die Beziehungen, in der die neuen Elemente zum Schlüsselelement gesetzt werden, aufgelistet:
- Als Strukturelement in der Beziehung einer strukturellen Zuordnung
- Als internes Thema in der Beziehung einer thematischen Auszeichnung
- Als externes Thema in der Beziehung einer thematischen Auszeichnung
- Als Person in der Beziehung einer thematischen Auszeichnung
- Als Projektphase in der Beziehung einer thematischen Auszeichnung
- Als Strukturtyp in der Beziehung einer thematischen Auszeichnung
- Ausnahme: Beim Import von Strukturelementen werden Strukturtypen mit den Schlüsselelementen in der Typisierungsbeziehung verknüpft.
- Als Projekt in der Beziehung einer Projektzuordnung
- Als Eigenschaft (alle systemseitig verfügbaren Felder werden aufgelistet)
Spezielle Fälle:
- Nur beim Import von Strukturelementen oder Themas (s. Bild 5 links):
- Als Notiz: Textinhalt wird automatisch zur Beschreibung der neuen Notiz (Beziehung: strukturelle Zuordnung oder thematische Auszeichnung der Notiz)
- Als Weblink: Textinhalt wird automatisch zur IRI des neuen Weblinks (Beziehung: strukturelle Zuordnung oder thematische Auszeichnung des Weblinks)
- Nur beim Import von Dokumenten (s. Bild 5 rechts):
- Als Dokumenttyp: Textinhalt wird zu einem externen Thema im Dokumenttyp-Schema (Beziehung: thematische Auszeichnung)
- Nur beim Import von Notizen:
- Als Notizart: Textinhalt wird zu einem externen Thema im Notizarten-Schema (Beziehung: thematische Auszeichnung)
Nach der Konfiguration aller gewünschten Importeinstellungen wird der eigentliche Importvorgang über den Button „Fertigstellen“ gestartet. Je nach Umfang der Daten kann der Vorgang einige Sekunden bis mehrere Minuten dauern. Nach Abschluss des Imports zeigt MonArch mehrere zusammenfassende Dialogseiten mit Informationen zum Ergebnis (s. Bild 6). Wurde auf der ersten Seite des Dialogs zusätzlich die Erstellung eines PDF-Berichts oder das Speichern der Konfiguration aktiviert, werden diese Dateien nun ebenfalls automatisch erzeugt.